نقدم لكم بحث عن مقاييس النزعة المركزية, مقاييس النزعة المركزية بالانجليزي,أهمية مقاييس النزعة المركزية والتشتت,مقاييس النزعة المركزية ومقاييس التشتت doc,مقاييس النزعة المركزية والتشتت ppt,مقاييس النزعة المركزية والمدى,العلاقة بين مقاييس النزعة المركزية,أفضل مقياس نزعة مركزية البيانات من المستوى الرتبى,مقاييس النزعة المركزية الوحيد الذي يمكن إيجادة للبيانات الاسمية هو, على كلام نيوز www.klamnews.com
بحث عن مقاييس النزعة المركزية 2020.
بحث عن مقاييس النزعة المركزية, مقاييس النزعة المركزية بالانجليزي,أهمية مقاييس النزعة المركزية والتشتت,مقاييس النزعة المركزية ومقاييس التشتت doc,مقاييس النزعة المركزية والتشتت ppt,مقاييس النزعة المركزية والمدى,العلاقة بين مقاييس النزعة المركزية,أفضل مقياس نزعة مركزية البيانات من المستوى الرتبى,مقاييس النزعة المركزية الوحيد الذي يمكن إيجادة للبيانات الاسمية هو.
تعريف مقاييس النزعة المركزية.
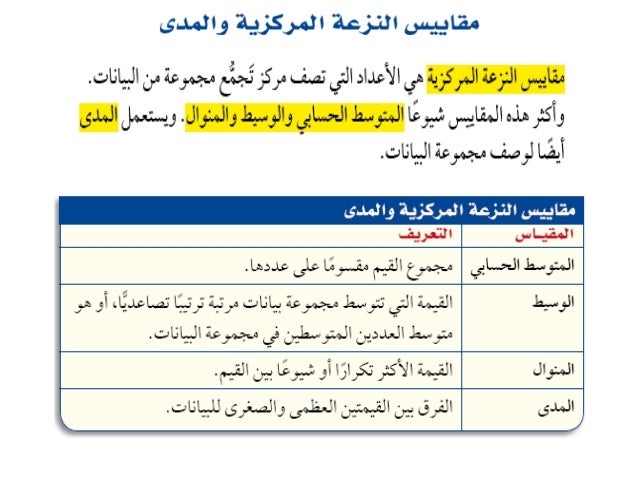
يهدف التحليل الإحصائي إلى استخراج معاني محددة تتعلق بالموضوع البحثي الذي يتناوله الباحث، وذلك تحقيقا لأهداف البحث وحيث أن التحليل الإحصائي هو عبارة عن مجموعة من الأرقام يتم ملاحظة العلاقات بينها ثم تفسيرها فإن من أهم الاعتبارات هي النقاط التي تتمحور حولها القيم والتي تسمى مقاييس النزعة المركزية، وكذلك مقدار الابتعاد عن تلك النقاط، والتي تسمى مقاييس التشتت.
وتبرز أهمية مقاييس النزعة المركزية والتشتت في البحث العلمي في كونها تعطي صورة متكاملة حول الظاهرة موضوع البحث، حيث توضح ميل عينة البحث إلى الارتكاز حول نقاط محددة، وكذلك القيم التي تبتعد عن تلك النقاط.
- تعود نشأة مصطلح النزعة المركزية أومصطلح مقياس النزعة المركزية إلى أواخر العشرينيات من القرن العشرين وهو من المفاهيم الإحصائية، ويتم تعريف مقاييس النزعة المركزية والتي يطلق عليها غالبًا مصطلح المتوسطات بأنها مجموعة القيم المركزية أو النموذجية المتخصصة في توزيع الاحتمالات، ويطلق عليها في بعض الأحيان مراكز التوزيع، ومن أهم مقاييس النزعة المركزية الأكثر شيوعًا المقاييس الوسط الحسابي والمتوسط، والتي يمكن من خلالها حساب الميل الأوسط لمجموعة محددة من القيم أو التوزيعات النظرية مثل التوزيع الطبيعي.
- أحيانًا يتم استخدام مقاييس النزعة المركزية للدلالة على ميل البيانات الكمية للتجمع حول بعض القيم المركزية، ويعد مقياس تشتت النزعة المركزية من أهم الخصائص المميزة للتوزيعات النظرية أو القيم في كثير من الأحيان، حيث عادًة ما يتناقض الاتجاه المركزي للتوزيع عند تشتيته أو حدوث تغييرات عليه، وتكمن أهمية مقياس تشتت النزعة المركزية في تحليل البيانات من خلال القدرة على تحديد أن لها ميل ونزعة مركزية قوية أو ضعيفة، ومن حيث الوصف يتم اعتبار العديد من مقاييس النزعة المركزية على أنها حل لمشكلة التباين الإحصائي
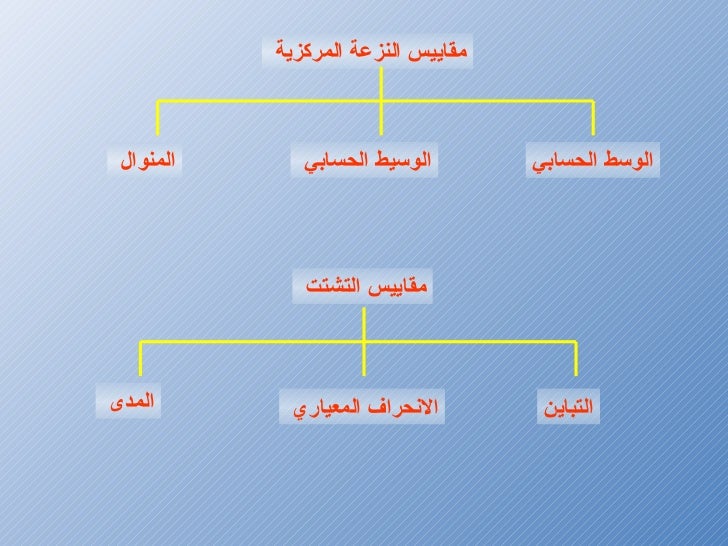
مقاييس النزعة المركزية (Measures of Central tendency) : تسمح لنا هذه المقاييس الاحصائية من الحصول على فكرة سريعة على طريقة تمركز البيانات. يمكن تلخيص أكثر المقاييس تداولا في هذا الجدول:
المتوسط الحسابي (Arithmetic mean)
وهو يمثل القيمة التي تتجمع حولها كل القيم. يتم حسابه عن طريق تقسيم مجموع قيم العينات على عدد العينات. يرمز له في العادة بـ: $\bar{X}$ أو $\mu$ ويحسب كالتالى: $\bar{X} = \frac{1}{n}\sum_{i=1}^n x_i$
الوسيط (median)
وهو القيمة التي يقع 50% من قيم العينات على كل من طرفيها حين ترتب تصاعديا أو نتازليا
المنوال (mode)
تمثل القيمة الأكثر ترددا بين قيم العينات
مخطط يوضح بعض مقاييس النزعة المركزية
-) مقاييس التشتت (Variation measure): في العادة مقاييس النزعة المركزية تكون غير كافية من أجل الحصول على نطرة متكاملة عن طريقة توزع البيانات اذ أنها تعطينا بعض المعلومات عن مكان تركز البيانات لكن لاتخبرنا مدى كثافة هذا التمركز. لهذه الأسباب نستعمل معايير التشتت لمعرفة تباعد البيانات فيما بينها. يمكن تلخيص مقاييس التشتت الأكثر الاستعمالا في الجدول التالي:
المدى (Range)
ويمثل الفرق بين أكبر وأصغر قيمة في البيانات $X_{max} – X_{min}$ لكن مشكلته أنه يتأثر بالقيم الشاذة
المدى الربيعي (Inter-Quartile range)
الهدف من هذا المقياس هو محاولة حساب مدى توزع البيانات بدون التأثر بالقيم الشاذة وذالك عن طريق اهمال القيم التي تتكون أقل من 25% من قيم البيانات (الربيع الأول $Q_1$) والقيم التي تتجاوز 75% من القيم (الربيع الثالث $Q_3$). إذن $IQR = Q_3 – Q1$
التباين (Variance)
يمثل التباين مقدار تباعد أو تشتت البيانات عن المتوسط الحسابي ويساوي متوسط مربع انحراف القيم عن المتوسط الحسابي يمثل في العادة بالرمز $\sigma^2$ أو $Var(X)$ أو $S^2$ يمكن تلخيصه بالعبارة التالية: $Var(X) = \frac{\sum_{i=1}^n (x_i – \bar{X})^2}{n} $
الانحراف المعياري (Standard Deviation)
يمثل الجذر التربيعي للتباين والهدف منه هو التعبير عن تشتت البيانات باأستعمال وحدة البيانات إذ أن التباين يستعمل وحدة البيانات مربع. يرمز له في العادة بـ $\sigma$ أو $S$. $\sigma = \sqrt{\sigma^2}$
معامل الاختلاف (Coefficient of Variation)
بستعمل عادة عندما نريد مقارنة التشتت بين عينتين لكن لكل عينة وحدة قياس مختلفة أو اذا كان المتوسط الحسابي مختلف بين العينتين. يتم حساب معامل الاختلاف كالتالي: $CV = \frac{S}{\bar{X}}$
بطبيعة الحال هناك عدة مقاييس أخرى لكن المقاييس المذكورة آنفا تعتبر من الأكثر شيوعا. هناك أيضا مجموعة من المخططات التي تساعدنا على تكوين صورة مرئية عن البيانات مثل المخططات الدائرية (Pie Chart) أو مخطط المستقيمات (Bar Chart). في حالة لما تريد المقارنة بين خصائص عدة مجموعات من البيانات حيث كل مجموعة تحتوي على الكثير من العناصر يمكن استعمال مثلا مخطط الرسم الصندوقي (Box plot) الذي يلخص القيم الخمس (في بعض الأحيان الستة) المحددة للعينة وهي : الربيع الأول $Q_1$ الوسيط $Q_2$, الربيع الثالث $Q_3$ بالاضافة إلى القيمة الصغرى و القيمة الكبرى, لكن في بعض الأحيان نفضل استبدال القيمة الصغرى بقيمة العشر الأول (10%) و قيمة القيمة الكبرى بالعشر التاسع (90%) وتمثيل القيم التي تكون خارج المجال [90%-10%] على شكل نقاط للدلالة على أنها قيم شاذة. في بعض التمثيلات أيضا تضاف علامة + للدلالة على المتوسط الحسابي.
-) مقاييس شكل التوزع (Distribution Shape) : تعطي هذه المقاييس لمحة عن شكل توزع البيانات مثل مقدار إلتواء (Skewness) وتفرطح (Kurtosis) منحنى توزيع البيانات عن المتوسط الحسابي.
بيان يوضح مبدأ الالتواء:
-) مقاييس الاستقلالية (Dependence) : تسمح لنا بحساب نسبة الاستقلالية بين عينتين. بما أننا في مرحلة التحليل الوصفي فإن هذه المرحلة لا تتطلب القيام بعمليات اختبار الفرضيات لكن فقط الحصول على فكرة أولية عن العلاقة بين العينات. في العادة في هذه الخطوة يتم حساب معامل الارتباط (correlation coefficient). يعتبر معامل ارتباط بيرسون (Pearson correlation coefficient) الاكثر شيوعا, في حالة كانت البيانات تخضع لترتيب معين بحيث تعطى رتبة لكل قيمة يتم استعمال معامل ارتباط سبيرمان (Spearman’s rank correlation coefficient) .
3. مرحلة التحليل الاستكشافي (Exploratory data analysis):
يمكن تعريف مصطلح التحليل الاستكشافي بأنه منهج (Approach) يتضمن العديد من التقنيات (في العادة مرئية) لتحليل البيانات واكتشاف علاقات غير معروفة وتساعدنا على تشكيل فرضيات جديدة أو حتى مجموعة بيانات جديدة. يساعدنا التحليل الاستكشافي أيضا في تصميم تجارب جديدة.
الهدف من التحليل الاستكشافي هو اعطاء المحلل نوعا من الحدس عن تصرف البيانات, مثلا هل هناك بنية سائدة في البيانات ؟ وما هي التوزيعة الأكثر تفسيرا للبيانات ؟ وماهي المتغيرات المؤثرة و المغيرات الغير مؤثرة في سلوك البيانات ؟ وهل يمكن تمثيل هذه البيانات في بُعْد أصغر من البعد الحالى ؟ وهل يمكن تجميع القيم في مجموعات؟ … إلخ. للاجابة عن هذه الأسئلة وغيرها نلجئ في هذه المرحلة إلى استعمال المخططات والبيانات بصورة مكثفة.
تم الترويج لهذا المنهج من طرف John Tukey من مختبرات بل والذي حث الاحصائين على اكتشاف البيانات و الذهاب إلى ماوراء البيانات لاكتشاف علاقات وتكوين فرضيات جديدة.
يمكن تصنيف التقنيات المستعملة في هذه المرحلة إلى نوعين: تقنيات مرئية وتقنيات تحليلية أو كمية
-) التقنيات المرئية: و هي التقنيات الأكثر استعمالا حيث أن هذه المرحلة تقوم على مبدأ أن التحليل البصري يُمكننا من رؤية العلاقات بشكل أسرع. من المخططات التي تستعمل في هذه المرحلة هناك الرسوم الصندوقية (Box plot), مخطط الفقاعات (Bubble chart), مخطط التشتت (Scatter plot), المدرجات التكرارية (Histograms).
من المخططات المهمة مخطط Q-Q اختصارا لـ Quantile-Quantile Plot والذي يمكن استعماله لمعاينة مدى مطابقة توزيع قيم العينة مع توزيعة نظرية (مثلا التوزيع الطبيعي) أو مع توزريع قيم عينة اخرى, بحيث يتم وضع قيم الـ Quantile (مثلا الاعشار) للعينية الأولى على المحور العمودي وقيم العينة الثانية في المحور الأفقي, فإذا اِصْطفت هذه القيم على محور 45 درجة للبيان يكننا أن تتشكل لدينا فكرة بأن التوزيعين متشابهين, للتأكد بطريقة أكثر دقة يمكننا استعمال اختبار Kolmogorov–Smirnov.
في مجال المعلوماتية الحيوية يمكن استعمال مخططات أخرى مثل مخطط مانهاتن (Manhattan Plot) التي تستعمل في دراسات الارتباطات الجينومية (GWAS) لدراسة علاقة الطفرات بالأمراض أو التغيرات النمطية بصفة عامة. حيث تُمَثَل الطفرات على المحور الأفقي ويُمَثَل احتمال وجود الارتباط على المحور العموي. تَمثِل القيم الكبرى الطفرات المسؤولة (ملونة بالأخضر في البيان).
يمكن أيضا استعمالات مخططات أخرى مثل الخرائط الحرارية (Heatmaps) والمخططات الدائرية (Circos plot)
شكل يوضح مخطط الخرائط الحرارية و المخططات الدائرية (مصدر الصورة أ, مصدر الصورة ب)
بالاضافة إلى العديد من المخططات التي لايمكن حصرها في هذا المقال. بالاضافة إلى ذالك يمكن القيام بعمليات تقسيم البيانات إلى مجموعات واظهارها.
-) التقنيات الكمية: تستعمل هذه التقنيات لحساب بعض القياسات و التأكد من أن البيانات تتبع توزعا من التوزيعات باستعمال مثلا اختبار Kolmogorov–Smirnov. يمكن أيضا القيام بعملية تحليل الانحدار (Regression Analysis) لتأكد من وجود علاقة خطية أو غير خطية بين عينتبن.
في حالة تحليل بيانات متتعدة المتغيرات نريد في العادة أن نقلص عدد المتغيرات لأنه في بعض الأحيان توجد متغيرات لاتساهم في الخصائص الاحصائية للبيانات بطريقة كبيرة. من بين التحيليلات التي يمكن القيام بها هو تحليل المركبات الرئيسية (PCA) الذي يساعد على اسقاط البيانات في فضاء ذوا أبعاد أقل. هناك أيضا خوارزميات عديدة مشابهة للـ PCA مثل خوارزمية EDA وغيرها.
من أهم التحليلات أيضا هو البحث عن المجموعات (Clustering) وتصنيف البيانات بطريقة آلية. الهدف من هذا التحليل هو معرفة الأشكال البيانية الخفية للبيانات واستخلاص بعض العلاقات بين العناصر. يوجد العديد من الخوارزميات التي يمكن استعمالها, لعل أسهلها وأكثرها استعمالا خوارزمية الـ k-means و التجميع الهرمي (Hierachical Clustering) وبعضها أكثر تعقيدا مثل الـ HDA وغيرها.
الصورة أ توضح عملية PCA زائد عملية تجميع. الصورة ب توضح عملية التجميع الهرمي (مصدر الصورة بتصرف)
4. مرحلة التحليل الاستدلالي (Inferential Data Analysis):
الهدف الرئيسي من هذه المرحلة هو تعميم النتائج أو الفرضيات واستنتاج خصائص مجتمع احصائي استنادا إلى خصائص العينات. لتوضيح الفكرة, لنفرض مثلا أننا نريد دراسة العلاقة بين التعبير الجيني و ميثيلة الحمض النووي, في الحالة المثالية يجب أن نحلل التعبير الجيني و ميثيلية الحمض النووي لكل البشر على سطح الأرض ونقوم بدراسة هذه العلاقة, لكن هذا مستحيل لعدة أسباب. فالذي نريد فعله هو أن نأخذ بعض العينات, مثلا 100 عينة, ونقوم بتحليلها ثم تعميم هذه النتائج على سكان الكرة الأرضية أو مايسمى بالمجتمع الاحصائي.
يوجد نوعين من التحليل الاستدلالي, الأول هو اختبار الفرضيات (Hypothesis Testing), مثلا نريد معرفة هل المتوسط الحسابي للعينة الأولى يساوي المتوسط الحسابي للعينة الثانية أو هل القيم المتحصل عليها موزعة عشوائيا أم بطريقة غير عشوائية. يمكن استعمال عدة طرقة لاختبار الفرضيات مثل اختبار تي (t-test) في حالة المقارنة بين عينتين أو اختبار ANOVA للمقارنة بين عدة عينات بالاضافة إلى عدة اختبارات أخرى. في العادة نحسب قيمة تسمي بالـ P-value والتي تمثل احتمال صحة الفرضية عشوائيا كلما كانت هذه القيمة صغيرة كلما زادت الدلالة الاحصائية للاختبار. في العادة نعتبر أن الاختبار ذو مدلول احصائي إذا كانت الـ P-value أقل من 0.05 أو 0.01 .
النوع الثاني من التحليل الاستدلالي هو التقدير الاحصائي (statistical estimation). وهو ينقسم أيضا إلى نوعين, النوع الأول هو التقدير النقطي (Point estimation), أبسط مثال على ذللك هو تقدير المتوسط العددي للمجتمع الاحصائي (ليس العينة). في هذا النوع من النوع من التقدير في العادة يكون لدينا نموذج احصائي (معادلة تضم علاقة بين المتغيرات العشوائية) ونحاول نقدير قيمة معاملات (Parameters) النموذج. يمكن بعدها استعمال هذا النموذج للتنبئ بقيم جديدة.
النوع الثاني من التقدير الاحصائي هو تقدير المجالات (Interval estimation) حيث نحاول تقدير مجالات الثقة, مثلا متى أكون واثقا بنسبة 95% من صحة قيمة المعامل الذي تم تقديره.
هناك مدرستان للتحليل الاستدلالي, المدرسة الاولى وهم التكراريون (frequentist) شعارهم هو أن معاملات النموذح الاحصائى ثابتة والبيانات عشوائية (models deterministic, data random) وسلاحهم هو طريقة الإمكان الأكبر (Maximum Likelihood Estimator) أو اختصارا MLE. من الطرف الآخر لدينا البايزيين (Baysians) وشعارهم هو أن معاملات النموذج الاحصائي عشوائية والبيانات ثابتة (مع أخطاء في الحساب طبعا) (models random, data deterministic) لهذا فهم يرون بضرورة اضافة بعض المعلومات المسبقة (prior belifs) للنموذج وسلاحهم نظرية بايز (Bayes Theory) . يتصارع ويتوافق في بعض الاحيان أنصار هذين المدرستين لكن موضوع هذا الصراع ليس موضوعنا
smile رمز تعبيري
.
في العادة في مجال المعلوماتية الحيوية يميل الباحثون إلى تطورير خوازميات مبنية على مبدأ نظرية بايز لأن استعمال الطرق التكرارية في أغلب الحالات يكون مستحيلا نظرا لحجم البيانات الكبير وكبر فضاء الاحتمالات مما يستلزم وقتا كبيرا. فاستعمال طرق بايز يسمح لنا بالحصول على قيم تقريبية تفي بالغرض.
- 5. مرحلة التحليل التنبؤي (Predictive Data Analysis):
- الهدف من هذه المرحلة هو استعمال نماذج احصائية (التي تم تقدير معاملاتها في المرحلة السابقة) للتنبئ بالنتائج المستقبلية. مثلا التنبئ بمجموعة الجينات التي تلعب دورا في السرطان استنادا إلى تعبيرها الجيني. بطبيعة الحال هناك مقدار من الخطئ أثنا القيام بالعملية ويجب إما تعديل النموذج الاحصائي أو القيام بتجارب للتأكد من صحة النتائج. لكن الهدف اللرئيسي من هذه المرحلة هو اقتراح مجموعة صغير من البيانات ذات دلالة احصائية لدراستها عوض دراسة كل عناصر العينة.
- 6. مرحلة التحليل السببي (Causal data Analysis):
- في الدراسات المتقدمة, نريد مثلا معرفة من من المتغيرات يسب من. تستعملا أيضا مجموعة من الأدوات الاحصائية للقيام بذالك. من بين الأسئلة التي تدرس بكثرة هي ايجاد العلاقة التنظيمية بين الجينات (Gene regulation) أو مثلا في الشبكات الاجتماعية نريد دراسة تاثير الأصدقاء على بعضهم البعض,… إلخ.
- 7. مرحلة التحليل الميكانيكي (Mechanistic data Analysis):
- الهدف من هذه المرحلة هو دراسة آليات حدوث التأثير بين المتغيرات. في العادة تكون التحاليل في هذه المرحلة صعبة وتكون الدراسة في العادة على نموذج صغير من البيانات. تستعمل هذه المرحلة كثيرا في مجال البيولوجية التخليقية (Sythetic Biology) لمحاكات مثلا تأثير التركيز المولي لبروتين من البروتينات على البروتينات الأخرى وتصميم بعض الأنظمة الاصطناعية للتحكم بالخلية. مثلا يمكن تصميم شبكات تفاعل بين بروتينات بحيث تنتج نوعا من البروتينات في وجود محفر من المحفزات. تستعمل البيولوجيا التخليقية في العادة من أجل التصنيع, مثلا الآن نستطيع برمجة البكتيريا لانتاج البلاستيك (Bioplastic) أو بعض الزيوت وهي مستعملة بكثرة في وقتنا الحالي